蓝凌是国内生态OA引领者、数智化办公专家及知识管理领军品牌,是智慧办公践行和推动者。21年深耕OA领域,坚持为传统企业办公赋能创新,成功服务数千家500强及行业百强企业实现数字化转型,引领大数据及AI时代下的智慧办公新方式。





藏经阁计划发布一年,阿里知识引擎有哪些技术突破?
- 作者:蓝凌OA办公系统
- 时间:2019-04-04 17:55:58

摘要:2018年4月阿里巴巴业务平台事业部——知识图谱团队联合清华大学、浙江大学、中科院自动化所、中科院软件所、苏州大学等五家机构,联合发布藏经阁(知识引擎)研究计划。藏经阁计划依赖阿里强大的计算能力(例如Igraph图数据库),和先进的机器学习算法(例如PAI平台)。计划发布一年以来,阿里知识图谱团队有哪些技术突破?今天一起来了解。
背景
藏经阁计划发布一年以来,我们对知识引擎技术进行了重新定义,将其定义成五大技术模块:知识获取、知识建模、知识推理、知识融合、知识服务,并将其开发落地。
其中知识建模的任务是定义通用/特定领域知识描述的概念、事件、规则及其相互关系的知识表示方法,建立通用/特定领域知识图谱的概念模型;知识获取是对知识建模定义的知识要素进行实例化的获取过程,将非结构化数据结构化为图谱里的知识;而知识融合是对异构和碎片化知识进行语义集成的过程,通过发现碎片化以及异构知识之间的关联,获得更完整的知识描述和知识之间的关联关系,实现知识互补和融合;知识推理是根据知识图谱提供知识计算和推理模型,发现知识图谱中的相关知识和隐含知识的过程。知识服务则是通过构建好的知识图谱提供以知识为核心的知识智能服务,提升应用系统的智能化服务能力。
经过一年的工作,在知识建模模块我们开发了Ontology自动搭建、属性自动发现等算法,搭建了知识图谱Ontology构建的工具;在知识获取模块我们研发了新实体识别、紧凑型事件识别,关系抽取等算法,达到了业界最高水平;在知识融合模块,我们设计了实体对齐和属性对齐的深度学习算法,使之可以在不同知识库上达到更好的扩展性,大大丰富了知识图谱里的知识;在知识推理模块,我们提出了基于Character Embedding的知识图谱表示学习模型CharTransE、可解释的知识图谱学习表示模型XTransE,并开发出了强大的推理引擎。
基于上面的这些技术模块,我们开发了通用的知识引擎产品,目前已经在全阿里经济体的淘宝、天猫、盒马鲜生、飞猪、天猫精灵等几十种产品上取得了成功应用,每天有8000多万次在线调用,日均离线输出9亿条知识。目前在知识引擎产品上,已经构建成功并运行着商品、旅游、新制造等5个垂直领域图谱的服务。
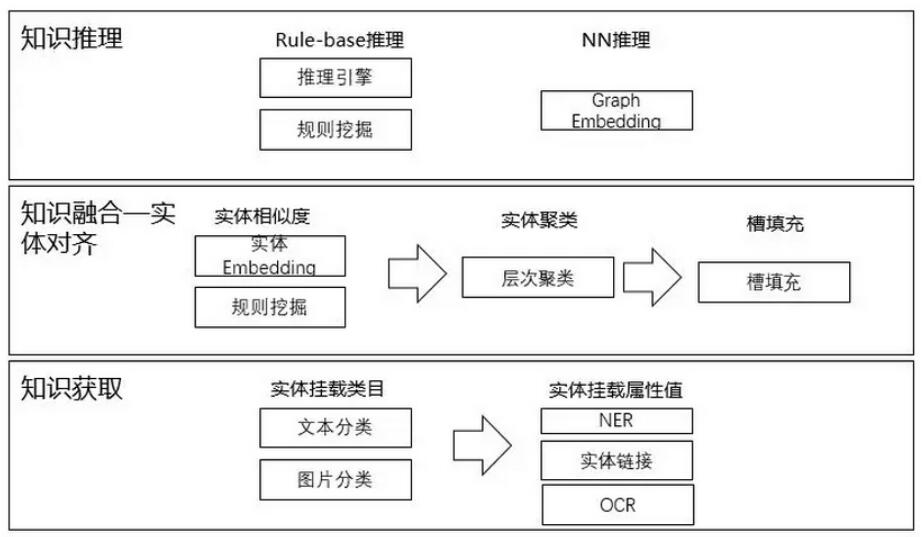
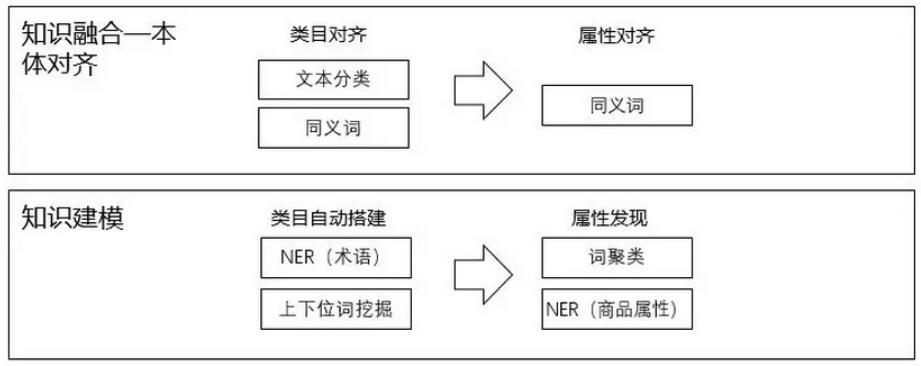
知识引擎四个层次图示
在每个模块的构建过程中,我们陆续攻克了一系列的技术问题。本文将选取其中的两项工作来介绍给大家:
1、在众包数据上进行对抗学习的命名实体识别方法
知识获取模块包含实体识别、实体链接、新实体发现、关系抽取、事件挖掘等基本任务,而实体识别(NER)又是其中最核心的任务。
目前学术界最好的命名实体识别算法主要是基于有监督学习的。构建高性能NER系统的关键是获取高质量标注语料。但是高质量标注数据通常需要专家进行标注,代价高并且速度较慢,因此目前工业界比较流行的方案是依赖众包来标注数据,但是由于众包人员素质参差不齐,对问题理解也千差万别,所以用其训练的算法效果会受到影响。基于此问题,我们提出了针对众包标注数据,设计对抗网络来学习众包标注员之间的共性,消除噪音,提高中文NER的性能的方法。
这项工作的具体网络框架如图所示:
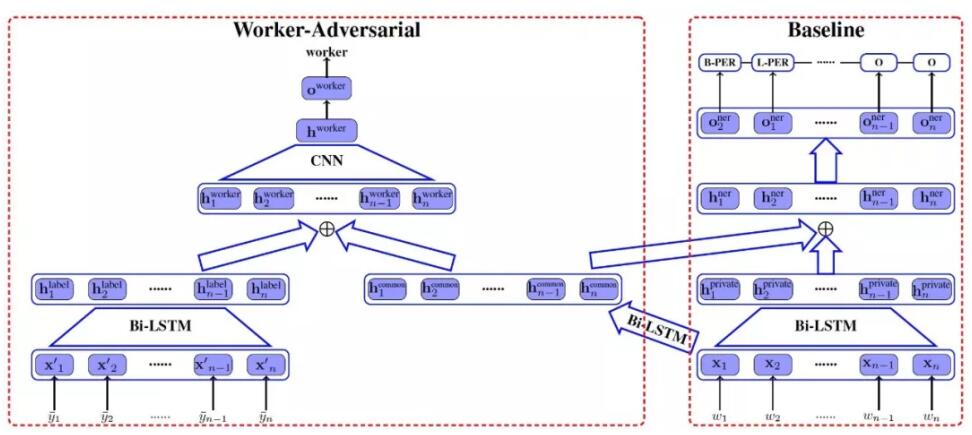
基于对抗网络的实体识别模型
标注员ID:对于各个标注员ID信息,我们使用一个Looking-up表,表内存储着每个WorkerID的向量表示。向量的初始值通过随机数进行初始化。在模型训练过程中,ID向量的所有数值作为模型的参数,在迭代过程中随同其他参数一起优化。在训练时每个标注样例的标注员,我们直接通过查表获取对应的ID向量表示。在测试时,由于缺乏标注员信息,我们使用所有向量的平均值作为ID向量输入。
对抗学习(WorkerAdversarial):众包数据作为训练语料,存在一定数量的标注错误,即“噪音”。这些标注不当或标注错误都是由标注员带来的。不同标注员对于规范的理解和背景认识是不同的。对抗学习的各LSTM模块如下:
l私有信息的LSTM称为“private”,它的学习目标是拟合各位标注员的独立分布;而共有信息的LSTM称为“common”,它的输入是句子,它的作用是学习标注结果之间的共有特征,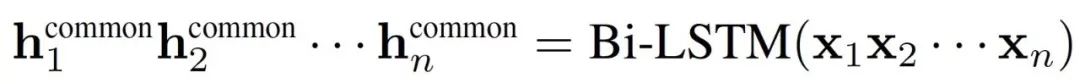 。
。
l标注信息的LSTM称为“label”,以训练样例的标注结果序列为输入,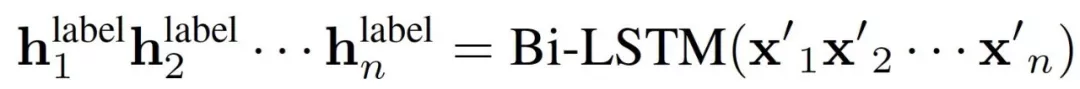 。
。
再通过标注员分类器把label和common的LSTM特征合并,输入给CNN层进行特征组合提取,最终对标注员进行分类。要注意的是,我们希望标注员分类器最终失去判断能力,也就是学习到特征对标注员没有区分能力,也就是共性特征。所以在训练参数优化时,它要反向更新。
在实际的实体识别任务中,我们把common和private的LSTM特征和标注员ID向量合并,作为实体标注部分的输入,最后用CRF层解码完成标注任务。
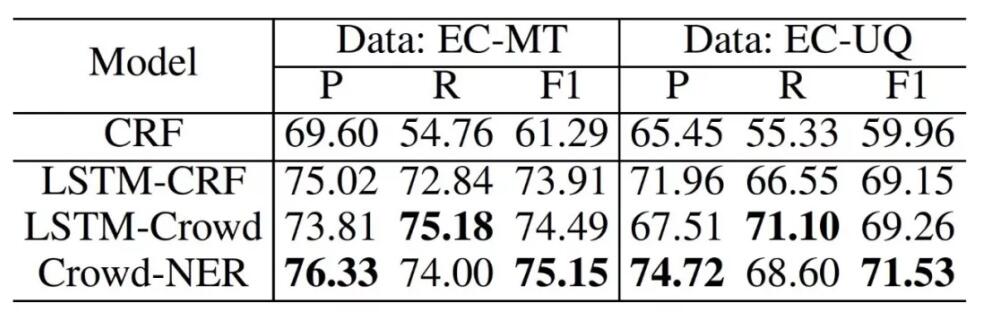
实验结果如图所示,我们的算法在商品Title和用户搜索Query的两个数据集上均取得最好的性能:
2、基于规则与graph embedding迭代学习的知识图谱推理算法
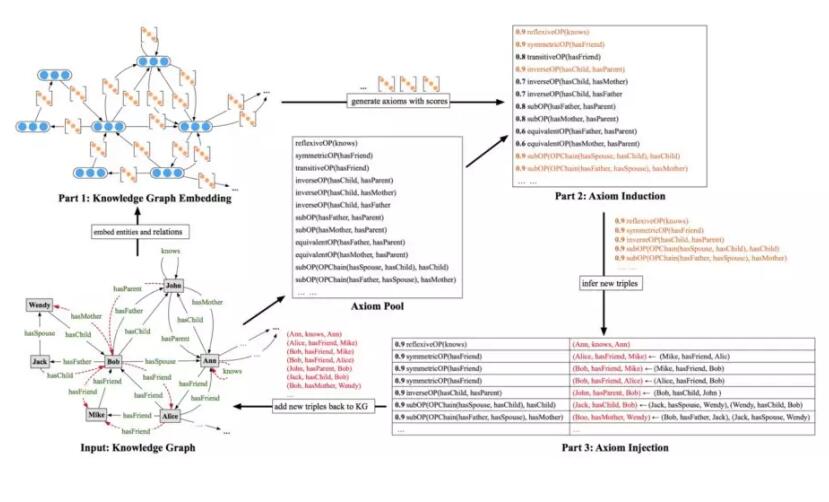
知识图谱推理计算是补充和校验图谱关系及属性的必不可少的技术手段。规则和嵌入(Embedding)是两种不同的知识图谱推理的方式,并各有优劣,规则本身精确且人可理解,但大部分规则学习方法在大规模知识图谱上面临效率问题,而嵌入(Embedding)表示本身具有很强的特征捕捉能力,也能够应用到大规模复杂的知识图谱上,但好的嵌入表示依赖于训练信息的丰富程度,所以对稀疏的实体很难学到很好的嵌入表示。我们提出了一种迭代学习规则和嵌入的思路,在这项工作中我们利用表示学习来学习规则,并利用规则对稀疏的实体进行潜在三元组的预测,并将预测的三元组添加到嵌入表示的学习过程中,然后不断进行迭代学习。工作的整体框架如图所示:
基于对抗网络的实体识别模型实验结果
嵌入学习优化的目标函数是:
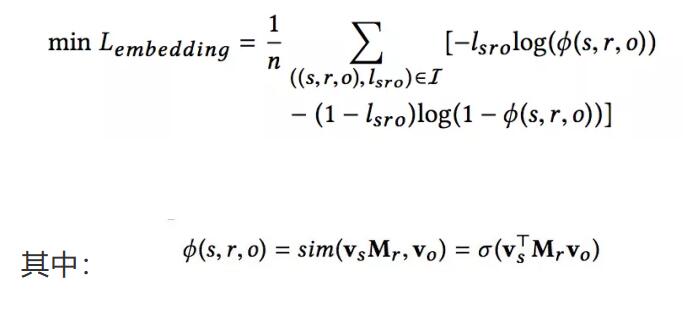
lsro表示三元组的标记,表示三元组的评分函数,vs表示图谱三元组中主语(subject)的映射,Mr表示图谱中两个实体间关系的映射,vo表示图谱三元组中宾语(object)的映射。
基于学习到的规则(axiom),就可以进行推理执行了。通过一种迭代策略,先使用嵌入(Embedding)的方法从图谱中学习到规则,再将规则推理执行,将新增的关系再加入到图谱中,通过这种不断学习迭代的算法,能够将图谱中的关系预测做的越来越准。最终我们的算法取得了非常优秀的性能:
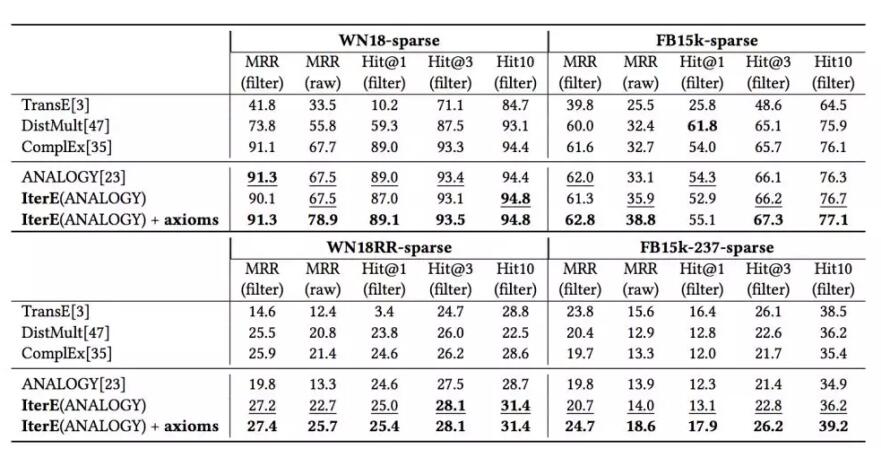
除了上述两项工作以外,在知识引擎技术的研发上我们还有一系列的前沿工作,取得了领先业界的效果,研究成果发表在AAAI、WWW、EMNLP、WSDM等会议上。
之后阿里巴巴知识图谱团队会持续推进藏经阁计划,构建通用可迁移的知识图谱算法,并将知识图谱里的数据输出到阿里巴巴内外部的各项应用之中,为这些应用插上AI的翅膀,成为阿里巴巴经济体乃至全社会的基础设施。
来源:阿里技术
上一篇: 员工童心满满,这种能量CEO该如何善用?